写在前面的说明
这个系列【ML-2020/21】大部分是课上内容的简单复述,之前上过但因为笔记写得很乱就忘了很多,所以重来一遍。与其看我这篇,不如直接去看视频,讲得还更生动。视频系列链接$\rightarrow$这里。
引入
根据上一篇【基本介绍】的内容可知,给GAN输入是一个向量,但这在实际中很不实用,我们更习惯用的是输入常见的信息比如语言文字,这就是Conditional GAN 所研究的东西。
举个例子,比如输入‘The Dog is running’,我们就希望生成如下图片:
这就是这篇要讲的东西。
Text-to-Image
Traditional Supervised Approach
首先,这可以看作是一个传统的监督学习,我们要的首先是一大堆数据集(图片),每张图片都需要一个对应的文字进行描述。简单来说流程如下:
但用这种方法会产生一个问题,比如说我们现在有一个文字描述为“car”,可能同时对应到以下两张图片,它们都是汽车只是方向不同:
我们用上面的方法训练出来的模型输出既要像左边也要像右边,最后就会产生这种现象:输入“car”,输出的图片是上面两种图片的平均,这可能会是一张没有意义的图。
所以这种传统的方法不行。
Conditional GAN
然后现在就要引进今天的主角了。
回顾一下,如果按照之前介绍的最原始的GAN,这个训练流程大致是这样的:
- 首先输入一组随机向量给Generation,产生数据(图片);\
- 将产生的图片输入Discriminator,借助真实图片,利用定义的function更新Discriminator的参数;\
- 随机再取一组噪音数据,利用上面更新后的Discriminator更新Generation的参数;\
- 重复上面两个步骤。
然而在Conditional-GAN中,我们输入给Generation的不再是单一的向量,同时还有(Condition)文字信息比如所“car”,借助这两个信息产生新的数据(图片)$x$;\
对于Discriminator,其输入除了之前产生的图片$x$,还有(Condition)文字信息$c$,输出是一个标量,这个标量描述以下两个方面:
- $x$是否是一张真实的图片(这点跟最原始的GAN一样);\
- $c$和$x$是否符合。
这个标量的评分标准如下:
- 高分(1分):\
a). 正确的文字与真实的图片。\- 低分(0分):\
a). 正确的文字与生成的图片;\
b). 错误的文字与真实的图片。
基本的训练流程如下:
D-Learning:\
1. 从database中取$m$个样本:$\left\{ (c^1,x^1),(c^2,x^2),…,(c^m,x^m)\right\}$ (这个对于Discriminator来说是要给高分的);\
2. 随机取样$m$个噪音样本:{$z^1,…,z^m$},这$m$个样本加上上面的文字信息$c$组成新的数据$(c^i,z^i)$;\
3. 通过Generation获取生成数据:{$\widetilde{x}^1,…,\widetilde{x}^m$},$\widetilde{x}^i=G(c^i,z^i)$\
4. 从database中取样新的$m$个数据{$\hat{x}^1,…,\hat{x}^m$}\
5. 更新Discriminator的参数$\theta_d$,以最大化下面这个方程:G-Leaarning:\
1. 取样$m$个噪声样本:{$z^1,…,z^m$};\
2. 从database中取$m$个condition:{$c^1,…,c^m$};\
3. 更新Generator的参数$\theta_g$,以最大化下面这个方程:
Discriminator 架构
常见的Discriminator架构如下: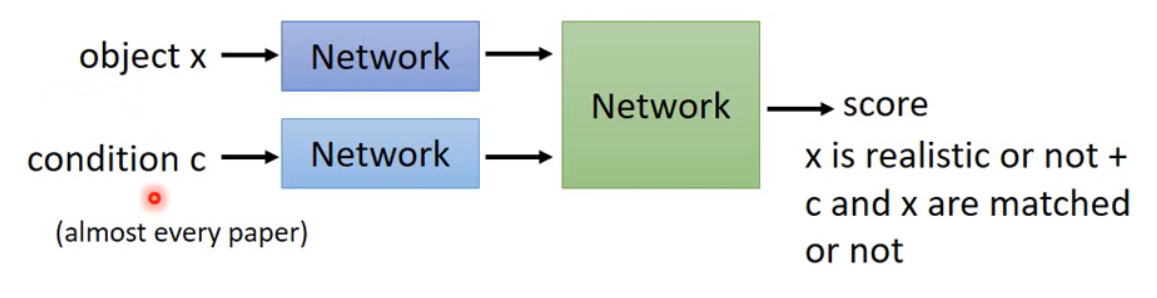
同时,又有人提出另一种架构: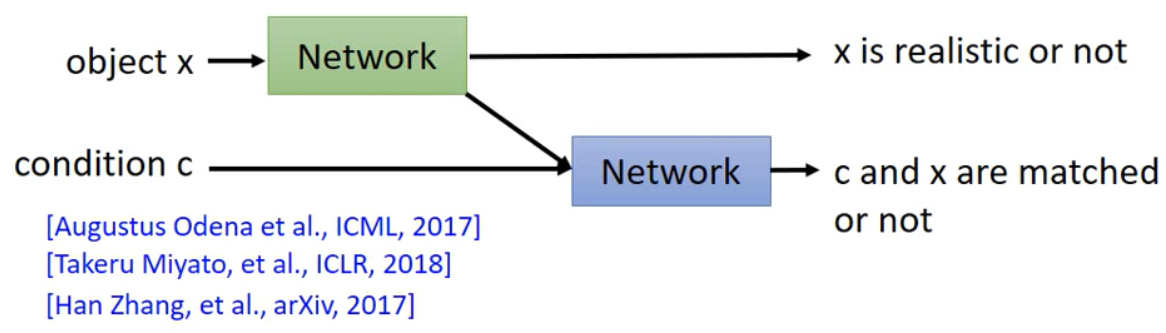
更进一步 —— Stack GAN
Stack-GAN技术能让模型的性能更加优秀,其基本的想法是:先产生小张的图,再根据小张的图产生大张的图。\
比如说,我们要产生$256\times 256$的图,但如果直接生成这么大的图,图很可能会坏,所以Stack-GAN在train的时候把整个训练过程拆分为两部分,大概流程是:
- 输入一个文字以及一段噪声,拼接,通过第一个Generator产生一个$64\times 64$的图;\
- 这个图片进入第一个Discriminator,判断其和文字是否match;\
- 然后第二部分,输入一个文字信息以及$64\times 64$的图片,产生一张$256\times 256$的图片;\
- 最后第二个Discriminator判断这个$256\times 256$的图片是不是足够真实。
具体可参看paper:StackGAN:Text to Photo-realistic Image Synthesis with Stack Generative Adversarial Network. 【ICCV, 2017】
Image-to-Image
这种即是:输入图片,输出也是图片。比如说黑白图片变彩色,白天变黑夜。
Traditional Supervised Approach
理论上也是可以用传统的监督学习实现,但也会遇到跟上面类似的问题,导致最终产生出来的图片特别模糊。
Conditional GAN
用GAN的话,以下图为例
也就是输入左边简单的图片,希望产生右边真实复杂的图。\
其基本流程就是:将简单的图片与噪音一起输入Generator,产生一张图片;接着将这张图片与原来简单的图片一起输入Discriminator,产生一个标量。这个标量可参看上面的解释。\
单单这么做的话,产生的图像虽然清晰,正确率也不错,但图片里可能会产生一些奇奇怪怪的部分。为了消除这种现象,我们可以加额外的约束,比如:在Generator的输出中,我们将产生的图片与真实图片作对比,也就是说,我们希望Generator产生的图片,既能骗过Discriminator,又跟目标图片相差不要太大,如此以来,模型性能会好很多。\
Patch GAN
如果图片很大张,那么Discriminator就不能直接接受整张Image,因为参数会很多,容易过拟合。所以措施是分区域输入,每次检查一小块,看这一小块是好的还是坏的,至于区域设置多大,这个就自己调了。